
键管理
本节将哪找单个键、遍历键、数据库管理三个维度对一些通用命令进行介绍。
-
单个键管理
-
键重命名
rename key newkey例如现有一个键值对,键位python,值为jedis:
127.0.0.1:6379> get python "jedis"下面操作将键python重命名为java:
127.0.0.1:6379> set python jedis OK 127.0.0.1:6379> rename python java OK 127.0.0.1:6379> get python (nil) 127.0.0.1:6379> get java "jedis"如果在rename之前,键java已经存在,那么它的值也将被覆盖,如下所 示:
127.0.0.1:6379> set a b OK 127.0.0.1:6379> set c d OK 127.0.0.1:6379> rename a c OK 127.0.0.1:6379> get a (nil) 127.0.0.1:6379> get c "b"为了防止强行rename,Redis提供了renamenx命令,确保只有newKey不 存在时才被覆盖,例如下面操作renamenx时,newKey=python已经存 在,返回结果是0代表没有完成重命名,所以键java和python的值没变:
127.0.0.1:6379> set java jedis OK 127.0.0.1:6379> set python redis-py OK 127.0.0.1:6379> renamenx java python (integer) 0 127.0.0.1:6379> get java "jedis" 127.0.0.1:6379> get python "redis-py"在使用重命名命令是,有两点需要注意:
- 由于重命名键期间会执行del命令删除旧的键,如果键对应的值比较 大,会存在阻塞Redis的可能性。
- 如果rename和renamenx中的key和newkey如果是相同的Redis3.2以前 会提示错误,Redis3.2以后返回OK
-
随机返回一个键
randomkey下面实例汇总,当前数据库有1000个键值对,randomkey命令会随即从中 挑选一个键:
127.0.0.1:6379> dbsize 1000 127.0.0.1:6379> randomkey "hello" 127.0.0.1:6379> randomkey "jedis" -
键过期
除了expire、ttl命令以外,Redis还提供了expireat、pexpire、 pexpireat、pttl、persist等一系列命令。
- expire key seconds:键在seconds秒后过期。
- expireat key timestamp:键在秒级时间戳timestamp后过期。
下面为键hello设置了10秒的过期时间,然后通过ttl观察他的过期剩余 时间(单位:秒),随着时间的推移,ttl逐渐变小,最终变为-2:
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> expire hello 10 (integer) 1 # 还剩7秒 127.0.0.1:6379> ttl hello (integer) 7 ... # 还剩0秒 127.0.0.1:6379> ttl hello (integer) 0 # 返回结果为-2,说明键hello已经被删除 127.0.0.1:6379> ttl hello (integer) -2ttl命令和pttl都可以查询键的剩余过期时间,但是pttl精度更高可以达 到毫秒级别,有3中返回值:
- 大于等于0的整数:键剩余的过期时间(ttl是秒,pttl是毫秒)。
- -1:键没有设置过期时间
- -2:键不存在
expireat命令可以设置键的秒级过期时间戳,例如如果需要将键hello在 2016-08-01 00:00:00(秒级时间戳为1469980800)过期,可以执行如 下操作:
127.0.0.1:6379> expireat hello 1469980800 (integer) 1除此之外,提供了毫秒级的过期方案:
- pexpire key milliseconds:键在milliseconds毫秒后过期。
- pexpireat key milliseconds-timestamp键在毫秒级时间戳 timestamp后过期。
但无论是使用过期时间还是时间戳,秒级还是毫秒级,在Redis内部最终 使用的都是pexpireat。
在使用Redis相关过期命令时,需要注意一下几点。
1)如果expire key的键不存在,返回结果为0:
127.0.0.1:6379> expire not_exist_key 30 (integer) 02)如果过期时间为负值,键会立即被删除,犹如使用del命令一样:
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> expire hello -2 (integer) 1 127.0.0.1:6379> get hello (nil)3)persist命令可以将键的过期时间清除:
127.0.0.1:6379> hset key f1 v1 (integer) 1 127.0.0.1:6379> expire key 50 (integer) 1 127.0.0.1:6379> ttl key (integer) 46 127.0.0.1:6379> persist key (integer) 1 127.0.0.1:6379> ttl key (integer) -14)对于字符串类型键,执行set命令会去掉过期时间 如下是Redis源码中,set命令的函数setKey,可以看到最后执行了 removeExpire(db,key)函数去掉了过期时间:
void setKey(redisDb *db, robj *key, robj *val){ if(lookupKeyWrite(db,key) == NULL){ dbAdd(db,key,val); }else{ dbOverwrite(db,key,val); } incrRefCount(val); //去掉过期时间 removeExpire(db,key); signalModifiedKey(db,key); }下面的例子证实了set会导致时间失效,因为ttl变为-1:
127.0.0.1:6379> expire hello 50 (integer) 1 127.0.0.1:6379> ttl hello (integer) 46 127.0.0.1:6379> set hello world OK 127.0.0.1:6379> ttl hello (integer) -15)Redis不支持二级数据结构(例如哈希、列表)内部元素的过期功能, 例如不能对列表类型的一个元素做过期时间设置。
6)setex命令作为set+expire的组合,不但是原子执行,同时减少了一 次网络通讯的时间。
-
迁移键
迁移键功能非常重要,因为有时候我们只想把部分数据由一个Redis迁移 到另一个Redis(例如从生产环境迁移到测试环境),Redis发展历程中 提供了move、dump + restore、migrate三组迁移键的方法,它们的实 现方式以及使用的场景不大相同,下面分别介绍。
(1)move
move key dbmove命令用于在Redis内部进行数据迁移,Redis内部可以有多个数据 库,由于多个数据库功能后面会进行介绍,这里只需要知道Redis内部可 以有多个数据库,彼此在数据上是相互隔离的,move key db就是把指定 的键从源数据库移动到目标数据库中,但笔者认为多数据库功能不建议在 生产环境使用。
(2)dump + restore
dump keyrestore key ttl valuedump + restore 可以实现在不同的Redis实例之间进行数据迁移的功 能,整个迁移的过程分为两步:
1)在源Redis,dump命令会将键值序列化,格式采用的是RDB格式。 2)在目标Redis上,restore命令将上面序列化的值进行复原,其中ttl 参数代表过期时间,如果ttl=0代表没有过期时间。
有关dump + restore有两点需要注意:第一,整个迁移过程并非原子性 的,而是通过客户端分步完成的。第二,迁移过程是开启了两个客户端连 接,所以dump的结果不是在源Redis和目标Redis之间进行传输,下面用 一个例子演示完整过程。
- 在源Redis上执行dump:
redis-source> set hello world OK redis-source> dump hello "\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ"- 在目标Redis上执行restore:
redis-target> get hello (nil) redis-targer> restore hello 0 "\x00\x05world\x06\x00\x8f<T\x04%\xfcNQ" OK redis-targget> get hello "world"上面2步对应的伪代码如下:
Redis sourceRedis = new Redis("sourceMechine", 6379); Redis targetRedis = new Redis("targetMechine", 6379); targetRedis.restore("hello", 0, sourceRedis.dump(key));(3)migrate
migrate host port key|“” destination-db timeout [copy] [replace] [keys key [key ...]]migrate命令也是用于在Redis实例间进行数据迁移的,实际上migrate 命令就是讲dump、restore、del三个命令进行组合,从而简化了操作流 程。migrate命令具有原子性,可以迁移多个键,有效地提高了迁移效 率。
其实现过程和dump + restore基本类似,但是有3点不太相同:第一,整 个过程是原子执行的,不需要再多个Redis实例上客气客户端的,只需要 在源Redis上执行migrate命令即可。第二,migrate名的数据传输直接 在源Redis和目标Redis上完成的。第三,目标Redis完成restore后会发 送OK给源Redis,源Redis接收后会根据migrate对应的选项来决定是否 在源Redis上删除对应的键。
下面对migrate的参数进行逐个说明:
- host:目标Redis的IP地址。
- port:目标Redis的端口。
- key|"":要迁移的键,如果当前需要迁移多个键,此处为空字符串
- destination-db:目标Redis的数据库索引
- timeout:迁移的超时时间(单位为毫秒)
- [copy]:如果添加此选项,迁移后并不删除源键。
- [replace]:如果添加次选项,migrate不管目标Redis是否存在该键都会正常迁移进行数据覆盖。
- [keys key[key ...]]:迁移多个键,例如要迁移key1、key2、key3,此处填写“keys key1 key2 key3”.
下面用示例演示migrate命令,为了方便演示源Redis使用6379,目标 Redis使用6380端口,现要将源Redis的键hello迁移到目标Redis中年, 会分为如下几种情况:
情况 1: 源Redis有键hello,目标没有:
127.0.0.1:6379> migrate 127.0.0.1:6380 hello 0 1000 OK情况 2: 源Redis和目标Redis都有键hello:
127.0.0.1:6379> get hello "world" 127.0.0.1:6379> get hello "redis"如果migrate命令没有加replace选项会受到错误提示,如果加了 replace会返回OK表明迁移成功:
127.0.0.1:6379> migrate 127.0.0.1:6380 hello 0 1000 (error) ERR Target instance replied with error:BUSYKEY Target key name already exists. 127.0.0.1:6379> migrate 127.0.0.1:6380 hello 0 1000 replace OK情况 3: 源Redis没有见hello。如下所示,此种情况会受到noKey 的提示:
127.0.0.1:6379> migrate 127.0.0.1:6380 hello 0 1000 NOKEY下面演示一下Redis迁移多个键的功能。
- 源Redis批量添加多个键:
127.0.0.1:6379> mset key1 value1 key2 value2 key3 value3 OK- 源Redis执行如下命令完成多个键的迁移:
127.0.0.1:6379> migrate 127.0.0.1:6380 "" 0 5000 keys key1 key2 key3 OK至此有关Redis数据迁移的命令介绍完了,下表总结了move、 dump + restore、migrate三种迁移方式的异同点。
命令 作用域 原子性 支持多个键 move Redis实例内部 是 否 dump + restore Redis实例之间 否 否 migrate Redis实例之间 是 是
-
-
遍历键
Redis提供了两个命令遍历所有的键,分别是keys和scan。
-
全量遍历键
keys pattern向一个空的Redis插入4个字符串类型的键值对
127.0.0.1:6379> dbsize (integer) 0 127.0.0.1:6379> mset hello world redis best jedis best hill high OK如果要过去所有的键,可以适应keys pattern命令:
127.0.0.1:6379> keys * 1) "hill" 2) "jedis" 3) "redis" 4) "hello"上面为了遍历所有的键,pattern直接使用星号,这是因为pattern使用 的是glob风格的通配符:
- * 代表匹配任意字符。 - ? 代表匹配资格字符。 - [] 代表匹配部分字符,例如[1,3]代表匹配1,3,[1-10]代表匹配 1到10的任意数字。 - \x用来做转义,例如要匹配星号、问好需要进行转义。下面操作匹配一j、r开头,紧跟edis字符串的所有键:
127.0.0.1:6379> keys [j,r]edis 1) "jedis" 2) "redis"例如下面操作会匹配到hello和hill这两个键:
127.0.0.1:6379> keys h?ll* 1) "hill" 2) "hello"当需要遍历所有键时(例如检查过期或闲置时间、寻找大对象等),keys 是一个很有帮助的命令,例如想删除所有以video字符串开头的键,可以 执行如下操作:
redis-cli keys video* | xargs redis-cli del但是如果考虑到Redis的单线程架构就不那么美妙了,如果Redis包含了 大量的键,执行keys命令很可能会造成Redis阻塞,所以一般建议不要再 生产环境下使用keys命令。但有时候确实有遍历键的需求怎么办,可以在 以下三种情况使用:
- 在一个不对外提供服务的Redsi从节点上执行,这样不会阻塞到客户端 的请求,但是会影响到主从复制。
- 如果确认键值总数确实比较少,可以执行该命令。
- 使用sxan命令进行渐进式的遍历所有键,可以有效防止阻塞。
-
渐进式遍历
scan,它能有效地解决keys命令存在的问题。和keys命令执行时会遍历 所有键不同,scan采用渐进式遍历的方式来解决keys命令可能带来的阻塞 问题,每次scan命令的时间复杂度是O(1),但是要真正实现keys的功 能,需要执行多次scan。Redid存储键值对实际使用的是hashtable的数 据结构,模型如下图:
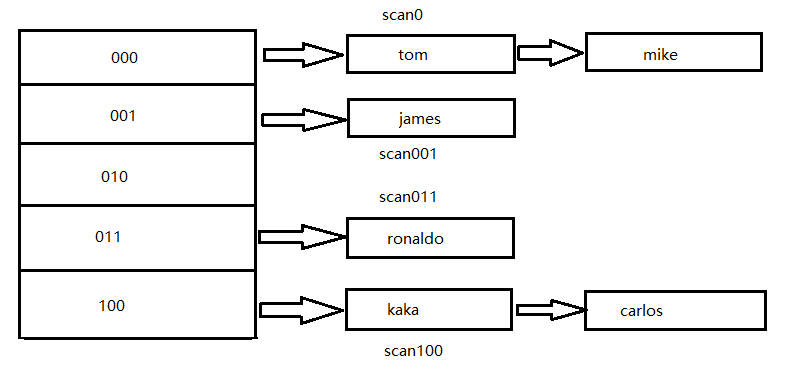
那么每次执行scan,可以想象成值扫描一个字典中的一部分键,知道将字 典中的所有键遍历完毕。scan的适应方法如下:
scan cursor [match pattern] [count number]-
cursor是必须参数,实际上cursor是一个游标,第一次遍历从0开始, 每次san便利玩都会返回当前有标的值,直到游标值为0,表示遍历结束。
-
match pattern是可选参数,他的作用的是做模式的匹配,这点和 keys的模式匹配很像。
-
count number是可选参数,他的作用是表明每次要遍历的键的个数, 默认值是10,此参数可以适当增大。
现有一个Redis有26个键(英文26个字母),现在要遍历所有的键,使用 scan命令效果的操作如下。第一次执行scan 0,返回结果分为两个部 分:第一个部分6就是下次scan需要的cursor,第二个部分是10个键:
127.0.0.1:6379> scan 0 1) "6" 2) 1) "w" 2) "i" 3) "e" 4) "x" 5) "j" 6) "q" 7) "y" 8) "u" 9) "b" 10) "o"使用新的cursor="6",执行scan 6:
127.0.0.1:6379> scan 6 1) "11" 2) 1) "b" 2) "n" 3) "m" 4) "t" 5) "c" 6) "d" 7) "g" 8) "p" 9) "z" 10) "a"这次得到的cursor="11",继续执行scan 11得到结果cursor变为0,说明 所有的键已经被遍历过了:
127.0.0.1:6379> scan 11 1) "0" 2) 1) "s" 2) "f" 3) "r" 4) "v" 5) "k" 6) "l"除了scan以外,Redis提供了面向哈希类型、集合类型、有序集合的扫描 遍历命令,解决诸如hgetall、smembers、zrange可能产生的阻塞问 题,对应的命令分别是hscan、sscan、zscan,它们的用法和scan基本 类似,下面以sscan为例子进行说明,当前集合有两种类型的元素,例如 分别以old:user和new:user开头,现需要将old:user开头的元素全部删 除,可以参考如下伪代码:
String key = "myset"; //定义pattern String pattern = "old:user"; //游标每次从0开始 String cursor = "0"; while(true){ //获取扫描结果 ScanResult scanResult = redis.sscan(key, cursor, pattern); List elements = scanResult.getResult(); if(elements != null && elements.size() > 0){ //批量删除 redis.srem(key, elements); } //获取新的游标 cursor = scanResult.getStringCursor(); //如果游标为0表示遍历结束 if("0".equals(cursor){ break; } }渐进式遍历可以有效地解决keys命令可能产生的阻塞问题,但是scan并非 完美无瑕,如果在scan的过程中有键的变化(增加、删除、修改),那么 遍历效果可能会碰到如下问题:新增的键可能没有遍历到,便利除了重复 的键等情况,也就是说scan并不能保证完整的遍历出所有的键。
-
-
-
数据库管理
Redis提供了几个面向Redis数据库的操作,他们分别是dbsize、select、 flashdb/flushll命令。
-
切换数据库
select dbIndex许多关系型数据库,例如MySQL支持在一个实例下有多个数据库存在,但 是与关系型数据库用字弗莱区分不同数据库名不同,Redis只是用数字作 为多个数据库的实现。Redis默认配置中是由16个数据库:
databases 16假设databases=16,select 0操作将切换到第一个数据库,select 15 选择最后一个数据库,但是0号数据库和15号数据库之间的数据没有任何 关联,生内置可以存在相同的键:
127.0.0.1:6379> set hello world # 默认进到0号数据库 OK 127.0.0.1:6379> get hello "world" 127.0.0.1:6379> select 15 # 切换到15号数据库 OK 127.0.0.1:6379[15]> get hello # 因为15号数据库和0号数据库是隔离的,所以get hello为空 (nil)那么能不能像使用测试数据库和正式数据库一样,把正式的放在0号数据 库,测试的数据库放在1号数据库,那么两者在数据上就不会彼此受影响 了。事实真有那么好吗?
Redis3.0中已经逐渐弱化这个功能,例如Redis的分数是实现Redis Cluster只允许使用0号数据库,只不过为了向下兼容老版本的数据库功 能,该功能没有完全废弃掉,下面分析一下为什么要废弃掉这个“优秀”的 功能呢?总结起来有三点:
-
Redis是单线程。如果使用多个数据库,那么这些数据库仍然是使用一 个CPU,彼此之间还是会受到影响的。
-
多数据库的使用方式,会让调试和韵下味不同业务的数据库变得困难, 假如有一个慢查询存在,依然会影响其他数据库,这样会是的别的业务方 定位问题非常的困难。
-
部分Redis的客户端根本就不支持这种方式。即使支持,在开发的时候 来回切换数字的数据库,很容易弄乱。
-
-
flushdb/flushall
flushdb/flushall命令用于清除数据库,两者的区别是flushdb只清除 当前数据库,fluahall会清除所有数据库。
flushdb/flushall命令可以非常方便的清理数据,但是也带来两个问 题:
- flushdb/flushall命令会将所有数据清除,一旦误操作后果不堪设想
- 如果当前数据库键值数量较多,flushdb/flushall存在阻塞Redis的 可能。
所以在使用fluashdb/flushall一定要小心谨慎。
-
本文由 Meridian 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jul 25,2019